Document details
2
1
T. Flohrer, R. Moissl, F. Schmitz

Abstract
Before being able to track objects in space, a radar system first needs to operate in search mode in order to find objects of interest. The unavoidable trade-off between those different radar modes and their individual efficiency can be optimised using radar resource management techniques. A fundamental goal of radar resource management is to make the allocation of resources as efficient as possible. Traditional search modes direct designated beams according to a predefined pattern. The positions of the search beams are calculated in advance so that they cover the volume of interest. Steering the search beam accordingly, e.g., scanning the search volume from its upper left to its lower right corner, ensures that the search volume is completely covered. It does not, however, exploit possible acquired knowledge about tracks and object positions and hence might waste resources on areas that do not include any objects.
In this paper, we propose a novel approach for using machine learning to allocate search beams in the search volume while leveraging acquired knowledge. Concretely, we model the problem as a multi-armed bandit (MAB) problem. The search beam positions are the actions (or, in MAB nomenclature, arms) which a so-called agent can choose. The rewards collected by the agent are the number of detected objects per chosen beam position at one time step. The overall goal is to maximize the total number of detected objects. That way, the radar search exemplifies the classic exploration-exploitation trade-off, which is addressed by MABs: exploring new beam positions might discover spots of high orbital activity, yet prevents the agent from exploiting beams which have been rewarding in preceding steps.
We present and evaluate our approach according to the following steps. Firstly, we introduce our MAB model and the implementation of different algorithms, among them the epsilon-greedy and the decayed epsilon-greedy algorithm. Our MAB model acts in an exemplary setting of a radar network consisting of a transmitter station and two receiver stations at fixed positions. The space objects to be detected are included in Two-Line Element (TLE) data format. The MAB algorithms can choose from a set of beam steering angles for a given amount of beams per radar station.
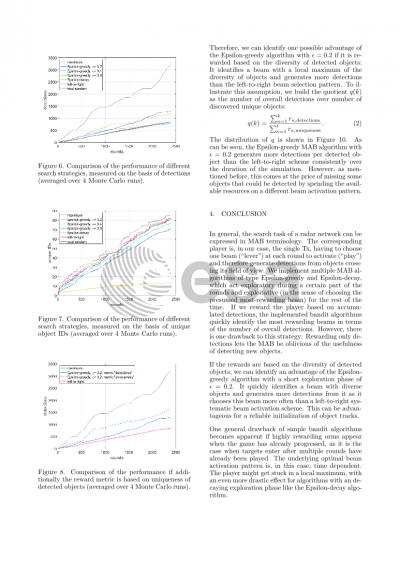
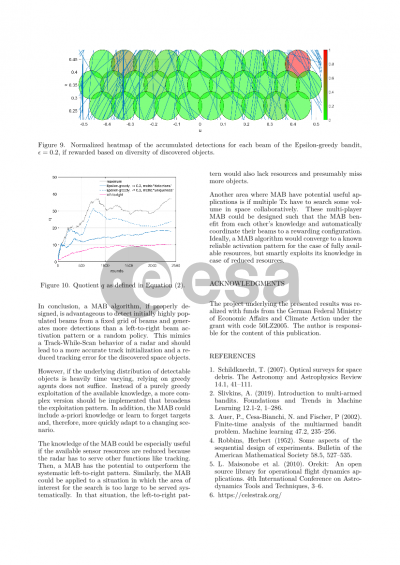
Then, the performance of the MAB algorithms is evaluated. This evaluation includes a regret analysis, i.e. calculating the difference between the performance of the algorithm and the optimal (in the sense of best in foresight) arm selection. We further compare our MAB approach to the performance of a classic search fence, in which the beams scan the search volume in a predefined, regular order. In contrast to classic MAB problems, the rewards in some radar search scenarios can be distributed very sparsely. That is, the algorithms obtain a reward seldom in comparison to the overall amount of actions when the amount of visible objects is small or when objects are in the search volume for only a short time. Therefore, we also quantify to which extent the MAB approach is suitable for such search scenarios and discuss its limitations.
Preview